Compute architecture for gaming
Compute architecture for gaming
The GF100 is of course intended for a massive gaming experience in terms of performance, but as mentioned in the intro already, the GPU's functionality is expanding more and fast to other segments as well.
What computing does in game terminology, is bringing added value to the gaming experience by not solely rendering the game but also bringing more to the users, more work to the GPU, C++ and Visual studio integration. The compute functions of GF100 will be diverse and wide, programmers will get several options to handle the GF100 compute engine and enhance your game experience.
GF100 will support Cuda C++, CUDA C, OpenCL, Direct Compute, PhysX and OptiX Ray Tracing.
What could a programmer do to enhance that gaming experience of yours with the help of Direct Compute ?:
- Image processing like Histograms, Convolutions, DOF, Blurs.
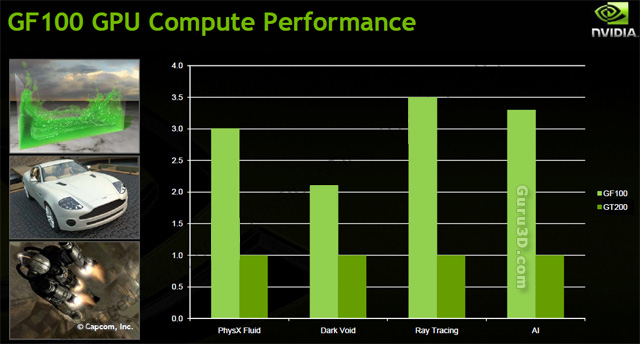
- Simulations - Physics fluids demo for example is 2x faster than GT200 (67 to 141 FPS), animations and AI for games, the last one (AI path finding) is very compute sensitive but is well suited for GPU compute. The result is roughly 3x faster than GT200.
- Hybrid Rendering
- Order independent transparency (OIT)
- Alias free shadows maps
- Ray tracing (4x faster than GT200)
- Voxel rendering
Compute, compute, compute .. it's the magic word that started for NVIDIA with CUDA. In this article we only mention some game compute options, but the reality is that more and more of today's application within the operating system get GPU accelerated or enhanced, this is all done on the compute side of things and as such NVIDIA invested massively in that. In fact their architecture was rearranged from SIMD to MIMD. Long story short: SIMD always has the advantage in raw peak operations per second. After all, it mainly consists of as many adders, floating-point units, shaders.
SIMD (Single Instruction, Multiple Data) refers to a parallel computer that runs the exact same program, thats the single instruction part on each of its simultaneously-executing parallel units. MIMD can pack more of their stuff into chips, too, using the same density.
MIMD (Multiple Instruction, Multiple Data) refers to parallel computing that runs an independent separate program thats the multiple instruction part on each of its simultaneously-executing parallel units. We feel the GPU becomes a huge floating point unit, which is great for games of course .. yet even better for GPGPU activity, compute and CUDA related applications.
To show you how important compute performance for NVIDIA, let me show you this chart, it explains it all. We are looking at least a minimum of a 2x compute increase over the last generation product.