
GPU Architecture
Digging a Little Deeper
The maximum per GPU shader cluster (Nvidia SM) for the Geforce RTX 4000 is now 144, which is the theoretical maximum. . As with Ampere, a cluster has 64 FP32 units and 64 FP32/INT32 units, four texture units, four tensor cores (Gen 4), a ray tracing core (Gen 3), and 128 KiB of L1 cache. This is how 18,432 FP32 shaders are assembled in one fully enabled ADA102 GPU. Half of which compute entirely is FP32 and the other half calculate in either FP32 or INT32. The configuration of the units relative to one another is identical to that of the Ampere; Nvidia has not altered this quantity. The raster operations pipeline of 16 units per raster engine also remains the same seen from Ampere. The Ada SM is equipped with 128 KB of Level 1 cache. Depending on the workload, this cache has a unified architecture that may be configured to operate as either an L1 data cache or shared memory. The complete AD102 GPU includes 18432 KB of L1 cache memory (compared to 10752 KB in GA102). Ada's Level 2 cache has been substantially redesigned relative to Ampere. AD102 is equipped with 98304 KB of L2 cache, a 16-fold increase over GA102's 6144 KB of L2 cache. All programs will benefit from the availability of such a vast cache memory pool, but sophisticated procedures such as ray tracing (especially path tracing) will gain the most.
A full AD102 GPU includes:
- 18432 CUDA Cores
- 144 RT Cores
- 576 Tensor Cores
- 576 Texture Units
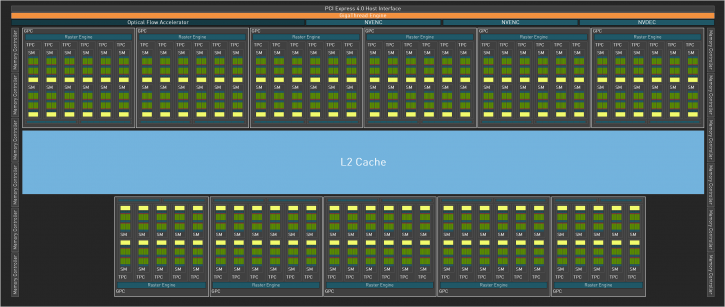
Geforce RTX 4000 block diagram by Ada Lovelace
Based on that alone the GeForce RTX 4090 is substantially quicker than the RTX 3090 Ti with its 10,752 shaders running a boost of 1,860 MHz. GeForce RTX 4090 however due to its base rate of 2,235 MHz and a boost clock of 2,520 MHz should offer yet another performance increase. The RTX 4080 16GB still has 9,728 shaders, and the RTX 4080 12GB has 7,680 shaders, but all announced variants have clock rates between 2.5 and 2.6 GHz boost.
NVIDIA GeForce RTX 4090
The new flagship GPU is the AD102-300, with 16384 CUDA cores and a boost clock of up to 2520 MHz and 23-power phases. This translates to a single-precision performance of 82.6 TFLOPS, 2.3x higher than its predecessor, the RTX 3090. The flagship Ada-based SKU will include 24GB of GDDR6X memory, with a peak bandwidth of 1 TB/s. This new card will require at least 100W more power than the 3090 Ti. NVIDIA confirms that this model will be available on October 12 for $1599.
NVIDIA RTX 4080 series
Also revealed are two 4080 graphics cards with the same model number but differing RAM and GPU specifications. The RTX 4080 16GB will have an AD103 GPU with 9728 CUDA cores, 16GB of GDDR6X memory clocked at 22.5 Gbps, and a 320W TDP. This model will be available in November for at least $1199. What was intended to be the RTX 4070 is now the RTX 4080 12GB. This model includes an AD104 GPU and 7680 CUDA cores. This model has 12GB GDDR6X RAM and a TDP of 285W, as the name says. This SKU is priced at $899 by NVIDIA. NVIDIA confirms that the cards will be available in November.
DLSS3
The NVIDIA Applied Deep Learning Research team has spent the past four years developing a frame generation technique that blends optical flow estimates with DLSS to enhance the gaming experience. The insertion of synthesized frames between existing frames enhances the frame rate and delivers a more fluid gaming experience. Optical flow estimation is frequently used in computer vision applications to measure the direction and amplitude of pixels' apparent motion between successively generated graphics frames or video frames. In the realms of 3D graphics and video, typical use cases have included minimizing latency in augmented and virtual reality, enhancing the smoothness of video playback, improving video compression efficiency, and stabilizing video cameras. Typical applications of deep learning include automobile and robotic navigation, video analysis and comprehension. Optical flow is comparable to the motion estimation component of video encoding, but its requirements for precision and consistency are significantly more demanding. As a result, many algorithms are employed. Since the Ampere GPU architecture, NVIDIA's GPUs have supported an optical flow engine (OFA) that employs cutting-edge algorithms to produce high-quality outputs. Ada's OFA unit delivers 300 TeraOPS (TOPS) of optical flow work (over 2x quicker than the Ampere generation OFA) and supplies essential data to the DLSS 3 network. The Ada OFA unit and new motion vector analysis algorithms are essential components that enable accurate and efficient frame production inside the new DLSS 3 technology architecture. This new DL-based frame generation algorithm increases frame rates by a factor of two in comparison to DLSS 2. When DLSS 3 is paired with the new RT Core and other Ada architecture improvements, Ada GPUs are up to four times quicker than their predecessors. DLSS 3 can also enhance performance when the CPU is the GPU's performance barrier. Microsoft Flight Simulator is a typical example of a CPU-limited game because of its physics and enormous draw distances. This reduces the performance advantages of conventional super-resolution systems. In this instance, though, DLSS 3's capacity to produce frames still delivers a performance boost of up to double.
