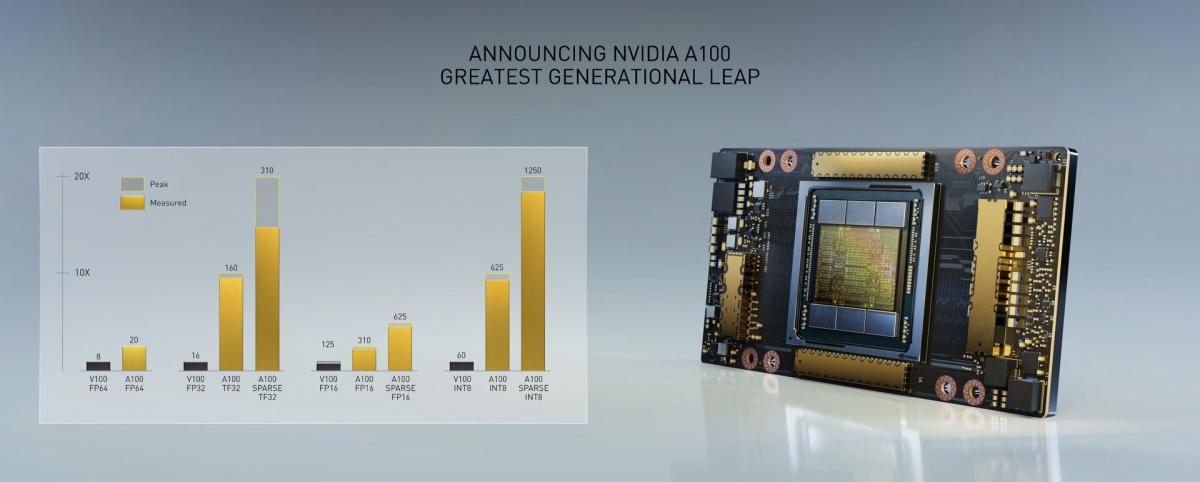
Nvidia has revealed initial details about the new GPU architecture Ampere. The successor to Volta is aimed at use in the data center for AI training and eep learning. The first ampere GPU A100 is said to offer 20 times more power than Volta in this scenario. The first product with A100 is the DGX A100.
The first chip built on Ampere, the A100, has some pretty impressive vital statistics. Powered by 54 billion transistors, it’s the world’s largest 7nm chip, according to Nvidia, delivering more than one Peta-operations per second. Nvidia claims the A100 has 20x the performance of the equivalent Volta device for both AI training (single precision, 32-bit floating point numbers) and AI inference (8-bit integer numbers). The same device used for high-performance scientific computing can beat Volta’s performance by 2.5x (for double precision, 64-bit). Each SM of the A100 comes with 64 FP32 cores and 32 FP64 cores. The A100 video card uses PCI Express 4.0 and Nvidia's proprietary NVLink interface for super-fast mutual communication, reaching a top speed of 600 GB/s. The tdp is set at 400 watts. You can see on the photos that there are six HBM2 stacks which together would account for a total of 40 gigabytes of video memory. Given the total memory bandwidth of 1550 GB/s, that is a 5120-bit memory bus.
A100 adds a powerful new third-generation Tensor Core that boosts throughput over V100 while adding comprehensive support for DL and HPC data types, together with a new Sparsity feature that delivers a further doubling of throughput. New TensorFloat-32 (TF32) Tensor Core operations in A100 provide an easy path to accelerate FP32 input/output data in DL frameworks and HPC, running 10x faster than V100 FP32 FMA operations or 20x faster with sparsity. For FP16/FP32 mixed-precision DL, the A100 Tensor Core delivers 2.5x the performance of V100, increasing to 5x with sparsity. New Bfloat16 (BF16)/FP32 mixed-precision Tensor Core operations run at the same rate as FP16/FP32 mixed-precision. Tensor Core acceleration of INT8, INT4, and binary round out support for DL inferencing, with A100 sparse INT8 running 20x faster than V100 INT8. For HPC, the A100 Tensor Core includes new IEEE-compliant FP64 processing that delivers 2.5x the FP64 performance of V100.
The GPU has a 7nm Ampere GA100 GPU with 6912 shader processors and 432 Tensor cores. Sized 826mm2 the GPU has 108 Streaming Multiprocessors x 64 Shader processors. A100 is not a fully enabled chip. Tesla A100 features 40GB of HBM2e memory.
Please note: a fully enabled GPU thus would have 8192 Cuda Cores and 48GB of HBM2 memory
A100 GPU streaming multiprocessor
The new streaming multiprocessor (SM) in the NVIDIA Ampere architecture-based A100 Tensor Core GPU significantly increases performance, builds upon features introduced in both the Volta and Turing SM architectures, and adds many new capabilities.
The A100 third-generation Tensor Cores enhance operand sharing and improve efficiency, and add powerful new data types, including the following:
- TF32 Tensor Core instructions that accelerate processing of FP32 data
- IEEE-compliant FP64 Tensor Core instructions for HPC
- BF16 Tensor Core instructions at the same throughput as FP16
40 GB HBM2 and 40 MB L2 cache
To feed its massive computational throughput, the NVIDIA A100 GPU has 40 GB of high-speed HBM2 memory with a class-leading 1.6 TB/sec of memory bandwidth – a 73% increase compared to Tesla V100. In addition, the A100 GPU has significantly more on-chip memory including a 40 MB Level 2 (L2) cache—nearly 7x larger than V100—to maximize compute performance. With a new partitioned crossbar structure, the A100 L2 cache provides 2.3x the L2 cache read bandwidth of V100. To optimize capacity utilization, the NVIDIA Ampere architecture provides L2 cache residency controls for you to manage data to keep or evict from the cache. A100 also adds Compute Data Compression to deliver up to an additional 4x improvement in DRAM bandwidth and L2 bandwidth, and up to 2x improvement in L2 capacity.
A100 GPU hardware architecture
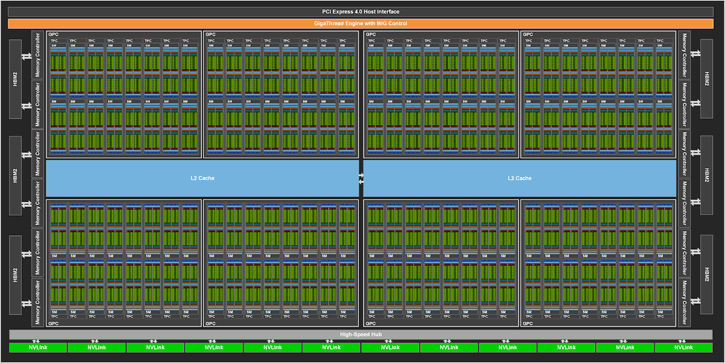
The NVIDIA GA100 GPU is composed of multiple GPU processing clusters (GPCs), texture processing clusters (TPCs), streaming multiprocessors (SMs), and HBM2 memory controllers.
The full implementation of the GA100 GPU includes the following units:
- 8 GPCs, 8 TPCs/GPC, 2 SMs/TPC, 16 SMs/GPC, 128 SMs per full GPU
- 64 FP32 CUDA Cores/SM, 8192 FP32 CUDA Cores per full GPU
- 4 third-generation Tensor Cores/SM, 512 third-generation Tensor Cores per full GPU
- 6 HBM2 stacks, 12 512-bit memory controllers
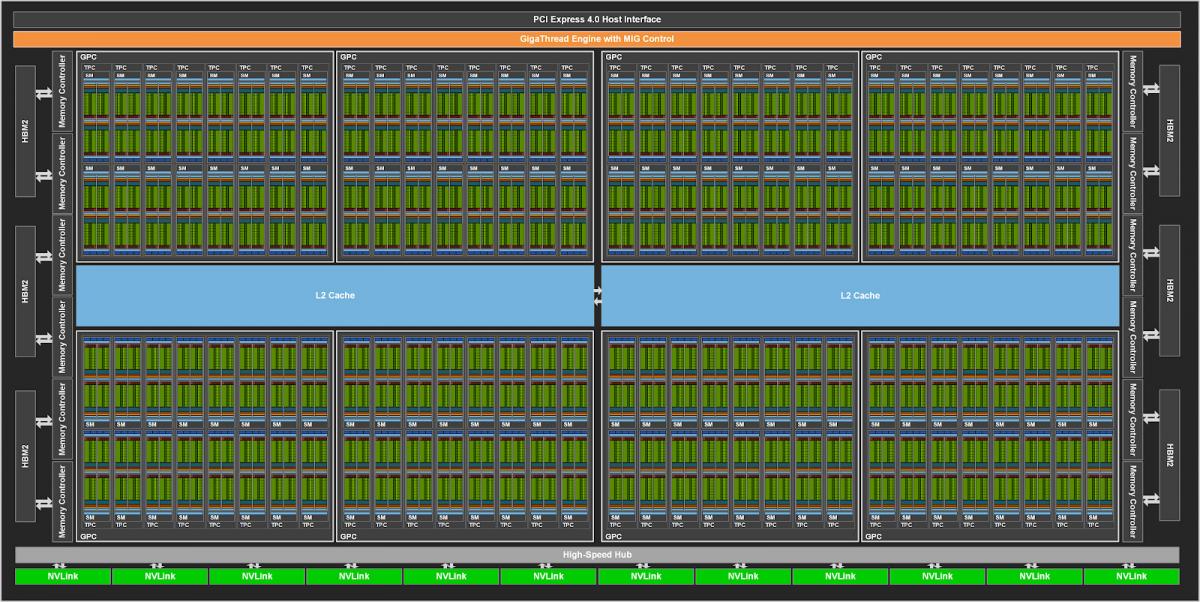
The A100 Tensor Core GPU implementation of the GA100 GPU includes the following units:
- 7 GPCs, 7 or 8 TPCs/GPC, 2 SMs/TPC, up to 16 SMs/GPC, 108 SMs
- 64 FP32 CUDA Cores/SM, 6912 FP32 CUDA Cores per GPU
- 4 third-generation Tensor Cores/SM, 432 third-generation Tensor Cores per GPU
- 5 HBM2 stacks, 10 512-bit memory controllers
Figure below shows a full GA100 GPU with 128 SMs. The A100 is based on GA100 and has 108 SMs.
| Data Center GPU | NVIDIA Tesla P100 | NVIDIA Tesla V100 | NVIDIA A100 |
| GPU Codename | GP100 | GV100 | GA100 |
| GPU Architecture | NVIDIA Pascal | NVIDIA Volta | NVIDIA Ampere |
| GPU Board Form Factor | SXM | SXM2 | SXM4 |
| SMs | 56 | 80 | 108 |
| TPCs | 28 | 40 | 54 |
| FP32 Cores / SM | 64 | 64 | 64 |
| FP32 Cores / GPU | 3584 | 5120 | 6912 |
| FP64 Cores / SM | 32 | 32 | 32 |
| FP64 Cores / GPU | 1792 | 2560 | 3456 |
| INT32 Cores / SM | NA | 64 | 64 |
| INT32 Cores / GPU | NA | 5120 | 6912 |
| Tensor Cores / SM | NA | 8 | 42 |
| Tensor Cores / GPU | NA | 640 | 432 |
| GPU Boost Clock | 1480 MHz | 1530 MHz | 1410 MHz |
| Peak FP16 Tensor TFLOPS with FP16 Accumulate1 | NA | 125 | 312/6243 |
| Peak FP16 Tensor TFLOPS with FP32 Accumulate1 | NA | 125 | 312/6243 |
| Peak BF16 Tensor TFLOPS with FP32 Accumulate1 | NA | NA | 312/6243 |
| Peak TF32 Tensor TFLOPS1 | NA | NA | 156/3123 |
| Peak FP64 Tensor TFLOPS1 | NA | NA | 19.5 |
| Peak INT8 Tensor TOPS1 | NA | NA | 624/12483 |
| Peak INT4 Tensor TOPS1 | NA | NA | 1248/24963 |
| Peak FP16 TFLOPS1 | 21.2 | 31.4 | 78 |
| Peak BF16 TFLOPS1 | NA | NA | 39 |
| Peak FP32 TFLOPS1 | 10.6 | 15.7 | 19.5 |
| Peak FP64 TFLOPS1 | 5.3 | 7.8 | 9.7 |
| Peak INT32 TOPS1 | NA | 15.7 | 19.5 |
| Texture Units | 224 | 320 | 432 |
| Memory Interface | 4096-bit HBM2 | 4096-bit HBM2 | 5120-bit HBM2 |
| Memory Size | 16 GB | 32 GB / 16 GB | 40 GB |
| Memory Data Rate | 703 MHz DDR | 877.5 MHz DDR | 1215 MHz DDR |
| Memory Bandwidth | 720 GB/sec | 900 GB/sec | 1.6 TB/sec |
| L2 Cache Size | 4096 KB | 6144 KB | 40960 KB |
| Shared Memory Size / SM | 64 KB | Configurable up to 96 KB | Configurable up to 164 KB |
| Register File Size / SM | 256 KB | 256 KB | 256 KB |
| Register File Size / GPU | 14336 KB | 20480 KB | 27648 KB |
| TDP | 300 Watts | 300 Watts | 400 Watts |
| Transistors | 15.3 billion | 21.1 billion | 54.2 billion |
| GPU Die Size | 610 mm² | 815 mm² | 826 mm2 |
| TSMC Manufacturing Process | 16 nm FinFET+ | 12 nm FFN | 7 nm N7 |
A100 HBM2 DRAM subsystem
As HPC, AI, and analytics datasets continue to grow and problems looking for solutions get increasingly complex, more GPU memory capacity and higher memory bandwidth is a necessity. Tesla P100 was the world’s first GPU architecture to support the high-bandwidth HBM2 memory technology, while Tesla V100 provided a faster, more efficient, and higher capacity HBM2 implementation. A100 raises the bar yet again on HBM2 performance and capacity. HBM2 memory is composed of memory stacks located on the same physical package as the GPU, providing substantial power and area savings compared to traditional GDDR5/6 memory designs, allowing more GPUs to be installed in systems. For more information about the fundamental details of HBM2 technology, see the NVIDIA Tesla P100: The Most Advanced Datacenter Accelerator Ever Built whitepaper.
The A100 GPU includes 40 GB of fast HBM2 DRAM memory on its SXM4-style circuit board. The memory is organized as five active HBM2 stacks with eight memory dies per stack. With a 1215 MHz (DDR) data rate the A100 HBM2 delivers 1.6 TB/sec memory bandwidth, which is more than 1.7x higher than V100 memory bandwidth. The A100 HBM2 memory subsystem supports single-error correcting double-error detection (SECDED) error-correcting code (ECC) to protect data. ECC provides higher reliability for compute applications that are sensitive to data corruption. It is especially important in large-scale, cluster computing environments where GPUs process large datasets or run applications for extended periods. Other key memory structures in A100 are also protected by SECDED ECC, including the L2 cache and the L1 caches and register files inside all the SMs.
A100 L2 cache
The A100 GPU includes 40 MB of L2 cache, which is 6.7x larger than V100 L2 cache.The L2 cache is divided into two partitions to enable higher bandwidth and lower latency memory access. Each L2 partition localizes and caches data for memory accesses from SMs in the GPCs directly connected to the partition. This structure enables A100 to deliver a 2.3x L2 bandwidth increase over V100. Hardware cache-coherence maintains the CUDA programming model across the full GPU, and applications automatically leverage the bandwidth and latency benefits of the new L2 cache. L2 cache is a shared resource for the GPCs and SMs and lies outside of the GPCs. The substantial increase in the A100 L2 cache size significantly improves performance of many HPC and AI workloads because larger portions of datasets and models can now be cached and repeatedly accessed at much higher speed than reading from and writing to HBM2 memory. Some workloads that are limited by DRAM bandwidth will benefit from the larger L2 cache, such as deep neural networks using small batch sizes. To optimize capacity utilization, the NVIDIA Ampere architecture provides L2 cache residency controls for you to manage data to keep or evict from the cache. You can set aside a portion of L2 cache for persistent data accesses. For example, for DL inferencing workloads, ping-pong buffers can be persistently cached in the L2 for faster data access, while also avoiding writebacks to DRAM. For producer-consumer chains, such as those found in DL training, L2 cache controls can optimize caching across the write-to-read data dependencies. In LSTM networks, recurrent weights can be preferentially cached and reused in L2.
The NVIDIA Ampere architecture adds Compute Data Compression to accelerate unstructured sparsity and other compressible data patterns. Compression in L2 provides up to 4x improvement to DRAM read/write bandwidth, up to 4x improvement in L2 read bandwidth, and up to 2x improvement in L2 capacity.
Multi-Instance GPU
The new Multi-Instance GPU (MIG) feature allows the A100 Tensor Core GPU to be securely partitioned into as many as seven separate GPU Instances for CUDA applications, providing multiple users with separate GPU resources to accelerate their applications. With MIG, each instance’s processors have separate and isolated paths through the entire memory system. The on-chip crossbar ports, L2 cache banks, memory controllers, and DRAM address busses are all assigned uniquely to an individual instance. This ensures that an individual user’s workload can run with predictable throughput and latency, with the same L2 cache allocation and DRAM bandwidth, even if other tasks are thrashing their own caches or saturating their DRAM interfaces. MIG increases GPU hardware utilization while providing a defined QoS and isolation between different clients, such as VMs, containers, and processes. MIG is especially beneficial for CSPs who have multi-tenant use cases. It ensures that one client cannot impact the work or scheduling of other clients, in addition to providing enhanced security and allowing GPU utilization guarantees for customers.
Third-generation NVIDIA NVLink
The third-generation of NVIDIA high-speed NVLink interconnect implemented in A100 GPUs and the new NVIDIA NVSwitch significantly enhances multi-GPU scalability, performance, and reliability. With more links per GPU and switch, the new NVLink provides much higher GPU-GPU communication bandwidth, and improved error-detection and recovery features. Third-generation NVLink has a data rate of 50 Gbit/sec per signal pair, nearly doubling the 25.78 Gbits/sec rate in V100. A single A100 NVLink provides 25-GB/second bandwidth in each direction similar to V100, but using only half the number of signal pairs per link compared to V100. The total number of links is increased to 12 in A100, vs. 6 in V100, yielding 600 GB/sec total bandwidth vs. 300 GB/sec for V100.
Support for NVIDIA Magnum IO and Mellanox interconnect solutions
The A100 Tensor Core GPU is fully compatible with NVIDIA Magnum IO and Mellanox state-of-the-art InfiniBand and Ethernet interconnect solutions to accelerate multi-node connectivity. The Magnum IO API integrates computing, networking, file systems, and storage to maximize I/O performance for multi-GPU, multi-node accelerated systems. It interfaces with CUDA-X libraries to accelerate I/O across a broad range of workloads, from AI and data analytics to visualization.
PCIe Gen 4 with SR-IOV
The A100 GPU supports PCI Express Gen 4 (PCIe Gen 4), which doubles the bandwidth of PCIe 3.0/3.1 by providing 31.5 GB/sec vs. 15.75 GB/sec for x16 connections. The faster speed is especially beneficial for A100 GPUs connecting to PCIe 4.0-capable CPUs, and to support fast network interfaces, such as 200 Gbit/sec InfiniBand. A100 also supports single root input/output virtualization (SR-IOV), which allows sharing and virtualizing a single PCIe connection for multiple processes or VMs.
DGX-A100
Nvidia has built eight of these A100s into a cloud accelerator system it calls the DGX-A100, which offers 5 petaflops. Each DGX-A100 offers 20x the peak performance of previous generation DGX systems. Unlike predecessors, the new systems can be used not only for AI training but also for scale-up applications (data analytics) and scale-out applications (inference). Nvidia’s figures have a single rack of five DGX-A100s replacing 25 data centre racks of CPUs, consuming 1/20th of the power and costing a tenth of the capex for an equivalent CPU-based system.
NVIDIA DGX A100
The DGX A100 system features eight Tesla A100 accelerations, offering up to 5 petaflops of performance. In NVIDIA’s own numbers, each of the Teslas offers 20x more peak performance than Volta-based DGX systems. NVIDIA is happy to demonstrate that a single rack of DGX1 system replaced 25 data center racks with CPUs, but only requiring 1/20 of the power and 1/10 of the investment. DGX-A100 systems are already installed at the US Department of Energy’s Argonne National Laboratory where they are being used to understand and fight Covid-19. Nvidia DGX A100 systems start at $199,000 and are shipping now.