Nvidia responded by arguing that AMD's comparison did not factor in specific optimizations for the H100 using TensorRT-LLM. They compared a single H100 against an eight-way configuration of H100 GPUs running the Llama 2 70B chat model. AMD countered by stating that Nvidia's benchmarks were selectively using inferencing workloads with its proprietary TensorRT-LLM on the H100. This was in contrast to the open-source and more commonly used vLLM method. Additionally, Nvidia compared its vLLM FP16 performance datatype for AMD's GPUs against the DGX-H100's TensorRT-LLM with FP8 datatype. AMD chose vLLM with FP16 due to its widespread use and lack of FP8 support in vLLM.
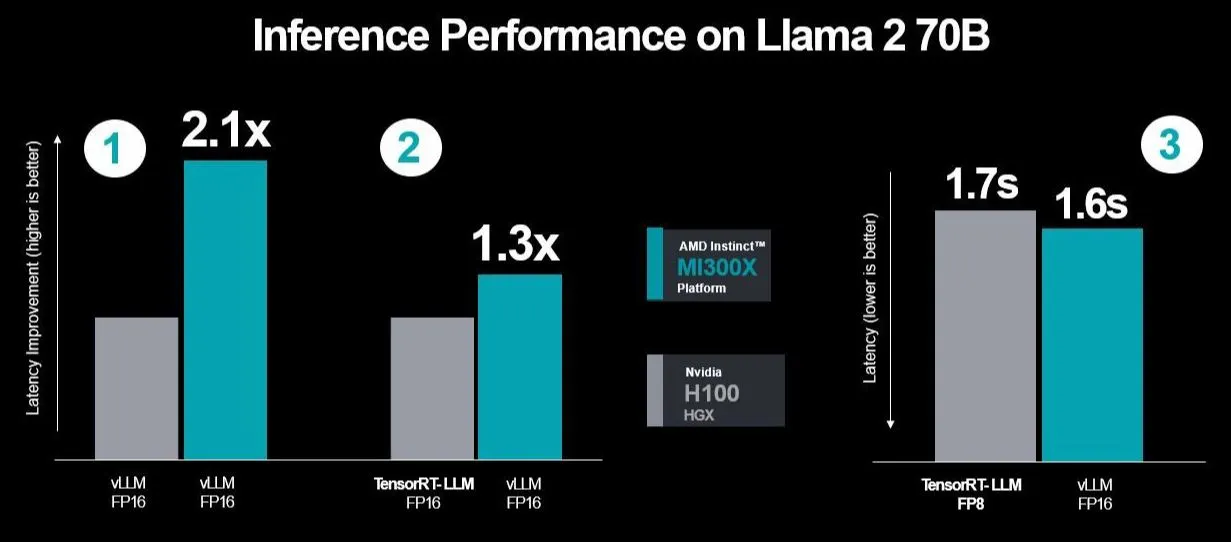
AMD also criticized Nvidia for not considering latency in their benchmarks, focusing instead on throughput performance. This, according to AMD, does not accurately reflect real-world server conditions. In its performance tests, AMD used Nvidia's TensorRT-LLM to measure latency differences between the MI300X and vLLM with FP16 against the H100 with TensorRT-LLM. The first test compared both GPUs using vLLM, and the second assessed MI300X's performance with vLLM against H100's TensorRT-LLM. These tests, replicating Nvidia's scenarios, showed improved performance and reduced latency for AMD. When running vLLM on both GPUs, AMD's MI300X achieved a 2.1x performance increase.
Nvidia is now expected to respond, particularly addressing the industry's preference for FP16 over FP8 in TensorRT-LLM's closed system and the potential move away from vLLM. As one commentator noted, the situation parallels the premium offerings of high-end products, where certain benefits are inherently included in the overall package.
