
Block Diagrams and Specs and new Features
The Turing Block Diagrams
In the chapter of this architecture review, I'd like to chart up and present to you the separated GPU block diagrams. Keep in mind that the specification on the 2080 and 2080 Ti differ slightly compared to the fully enabled GPU, as the GPUs have disabled shader / RT / Tensor partitions. So the block diagrams you see here are based upon the fully enabled GPUs. Only the GeForce RTX 2070 is a fully enabled TU106 chip.
 | ||||||
|---|---|---|---|---|---|---|
| GeForce | RTX 2080 Ti FE | TU102 GPU | RTX 2080 FE | TU104 GPU | RTX 2070 FE | TU106 GPU |
| GPU | TU102 | TU102 | TU104 | TU104 | TU106 | TU106 |
| Node | TSMC 12 nm FFN | |||||
| Die Size mm² | 754 | 545 | 445 | |||
| Shader cores | 4352 | 4608 | 2944 | 3072 | 2304 | 2304 |
| Transistor count | 18.6 Billion | 18.6 Billion | 13.6 Billion | 13.6 Billion | 10.8 Billion | 10.8 Billion |
| Base frequency | 1350 MHz | 1515 MHz | 1410 MHz | |||
| Boost frequency | 1635 MHz | 1800 MHz | 1710 MHz | |||
| Memory | 11GB GDDR6 | 12GB GDDR6 | 8GB GDDR6 | 8GB GDDR6 | 8GB GDDR6 | 8GB GDDR6 |
| Memory frequency | 14 Gbps | 14 Gbps | 14 Gbps | 14 Gbps | 14 Gbps | 14 Gbps |
| Memory bus | 352-bit | 384-bit | 256-bit | 256-bit | 256-bit | 256-bit |
| Memory bandwidth | 616 GB/s | 672 GB/s | 448 GB/s | 448 GB/s | 448 GB/s | 448 GB/s |
| RT cores | 68 | 72 | 46 | 48 | 36 | 36 |
| Tensor cores | 544 | 576 | 368 | 384 | 288 | 288 |
| Texture units | 272 | 288 | 184 | 192 | 144 | 144 |
| ROPs | 96 | 96 | 64 | 64 | 64 | 64 |
| TDP | 260W | 225W | 185W | |||
| Power connector | 2x 8-pin | 8+6-pin | 8-pin | |||
| NVLink | Yes | Yes | Yes | Yes | No | No |
| Performance (RTX Ops) | 78T RTX-Ops | 60T RTX-Ops | 45T RTX-Ops | |||
| Performance (RT) | 10 Gigarays/s | 8 Gigarays/s | 6 Gigarays/s | |||
| TFlops fp32 | 14.2 / 13.4 | 10.6 / 10 | 7.9 / 7.5 | |||
| Max Therm degree C | 89 | 89 | 89 | |||
| price | $ 1199 | $ 799 | $ 599 | |||
 |
||||||
RT cores and hardware-assisted raytracing
NVIDIA is adding 72 RT cores on its full Turing GPU. By utilizing these, developers can apply something that I just referred to as hybrid raytracing. You still are performing your shaded (rasterization) rendering, however, developers can apply real-time raytraced environmental functionality like reflections and refractions of light onto objects. Think of sea, waves, and water reflecting precise and accurate world reflections and lights. You can also think of a fire or explosion, bouncing light off walls and reflecting in the water. It's not just reflections bouncing the right light rays but also the other way around, shadows. Where there's light there should be a shadow, 100% accurate soft shadows can now be computed. It has been really hard in the traditional shading engine to create accurate and proper shadows, this is now also something possible with raytracing. Also, raytraced ambient occlusion and global illumination are something that is going to be a big thing. Never have these things been possible as raytracing is all about achieving realism in your game.
Please watch the above video
Now, I can write up three thousand words and you'd still be confused as to what you can achieve with raytracing in a game scene. Ergo I'd like to invite you to look at the video above that I recorded at a recent NVIDIA event. It's recorded by hand with a smartphone, but even in this quality, you can easily see how impressive the technology is by looking at several use-case examples that can be applied to games. Allow me to rephrase that, try to extrapolate the different RT technologies used, and imagine them in a game, as that is the ultimate goal we're trying to achieve here.
So how does DX-R work?
Normally lights or bounced, reflected, refracted, etc. light rays hit an object, right? Let's take the position you are sitting in and look around you. Anything you can see is based on light rays. That's colors and lights bouncing off each other and of all objects. Thinking about what and, more importantly, how you are seeing things inside your room right there is already complicated. But basically, if you take a light source, that source will transmit light rays that bounce off the object you are looking at.
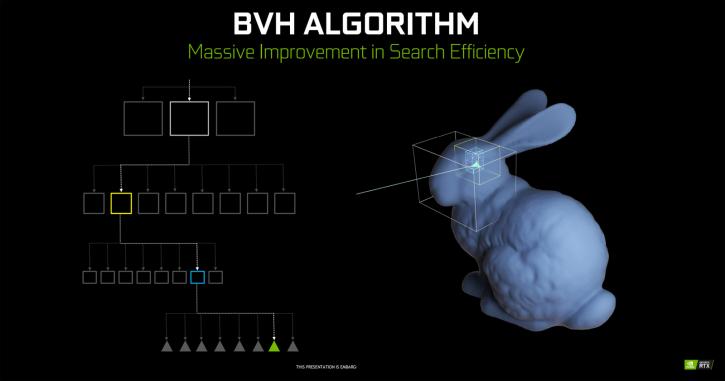
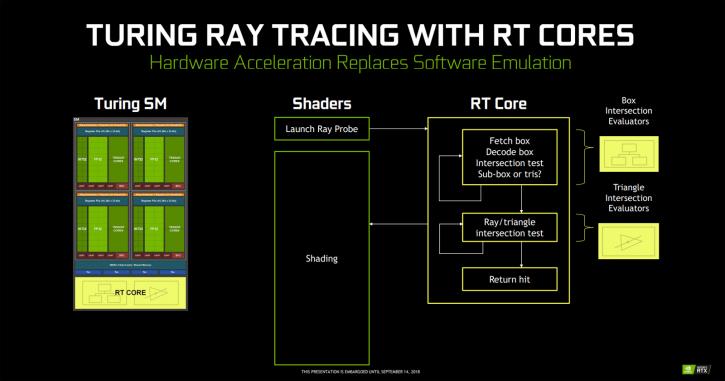
Well, DXR is reversing that process. By applying a technology called BVH = “Bounding Volume Hierarchy”. DirectX Raytracing is using an algorithm where an object is divided into boxes (the resolution/number of boxes for more precision can be programmed by the developer), so boxes and even more boxes until it hits triangles. The fundamental idea is that not all triangles get or need to be raytraced, but only a certain amount of (multitude) boxes. The architecture in the RT core basically has two fundamental functions, one checks boxes, the other triangles. It's kind of working like a shader for rasterization code but specifically for rays. Once the developer has decided what level of boxes on a certain object is applied, that (and each) box will fire off a ray into the scene. And that ray will bounce and hit other objects, lights and so on. Once that data is processed you have shading going in, deep learning and raytracing. NVIDIA is doing roughly 50-50 shading and raytracing on an RT enhanced scene.
So how does that translate into games? The best example is to show you my (again, recorded with a smartphone) Battlefield 5 recording. While in early alpha stages, you will likely be impressed as to what is happening here as explained really nicely by fellow guru pSXAuthor in the forums. What basically is shown here is the difference between screen space reflections (SSR) and raytraced reflections. SSR works by approximating raytracing in screen space. For each and every pixel on a reflective surface a ray is fired out and the camera's depth and colour buffers are used to perform an approximation to raytracing (you can imagine drawing a line in 3D in the direction of the reflected light, reading the depth of each pixel until the line disappears behind another surface - nominally this will be the reflected point if the intersection point is close to the line - otherwise it is probably an occlusion - doing it efficiently and robustly is a little more involved than this but this explanation is very close to the reality). This approximation can be quite accurate in simple cases, however, because the camera's image is being used: no back facing surfaces can ever be reflected (you will never see your face in a puddle!), nothing off screen can be reflected, and geometry behind other geometry from the point of view of the camera can never be reflected. This last point explains why the gun in an FPS causes areas in the reflections to be hidden - the reason is very simple: those pixels should be reflecting something which is underneath the gun in the camera's 2D image. Also, this explains why the explosion is not visible in the car door: it is out of shot. Actually: it also appears that the BF engine does not reflect the particle effects anyway (probably reflection is done earlier in the pipeline than the particles are drawn). Using real raytracing for reflection avoids all of these issues (at the cost of doing full raytracing obviously), that process is managed over the RT cores running Microsoft's DXR.
Microsoft can count on cooperation from the software houses. The two largest publicly available game engines, Unreal Engine 4 and Unity will, for example, support it. EA is also using its Frostbite and Seed engines to implement DXR.

The vast majority of the market is therefore already covered. So the functionality of RT cores / RTX will find its way to game applications and engines like Unreal Engine, Unity, Frostbite... they have also teamed up with game developers like EA, Remedy, and 4A Games. The biggest titles this year, of course, will be the new Tomb Raider and Battlefield 5. Summing things up, DXR, or raytracing in games as a technology, is a game changer. How it turns out on Turing for actual processing power, remains to be seen until thoroughly tested.
DLSS High-Quality Motion Image generation
Deep Learning Super Sampling - DLSS is a supersampling AA algorithm that uses Tensor core-accelerated neural network inferencing in an effort to create what NVIDIA refers to as high-quality super sampling like anti-aliasing. By itself the GeForce RTX graphics card will offer a good performance increase compared to the last gen counterparts, NVIDIA mentions roughly 50% higher performance based on 4K HDR 60Hz conditions for the faster graphics cards. That obviously excludes real-time raytracing or DLSS, that would be your pure shading performance. Deep learning can now be applied in games as an alternative AA (anti-aliasing) solution. Basically, the shading engine renders your frame, passes it onwards to the Tensor engine, which will super sample and analyze it based on an algorithm (not a filter), apply its AA and pass it back. The new DLSS 2X function will offer TAA quality anti-aliasing at little to no cost as you render your games 'without AA' on the shader engine, however, the frames are passed to the Tensor engines who apply supersampling and perform anti-aliasing at a quality level comparable to TAA, and that means super-sampled AA at very little cost. At launch, a dozen or so games will support Tensor core optimized DLAA, and more titles will follow. Contrary to what many believe it to be, Deep Learning AA is not a simple filter. It is an adaptive algorithm. The setting, in the end, will be available in the NV driver properties with a slider. Here's NVIDIA's explanation; to train the network, they collect thousands of “ground truth” reference images rendered with the gold standard method for perfect image quality, 64x supersampling (64xSS). 64x supersampling means that instead of shading each pixel once, we shade at 64 different offsets within the pixel, and then combine the outputs, producing a resulting image with ideal detail and anti-aliasing quality. We also capture matching raw input images rendered normally. Next, we start training the DLSS network to match the 64xSS output frames, by going through each input, asking DLSS to produce an output, measuring the difference between its output and the 64xSS target, and adjusting the weights in the network based on the differences, through a process called backpropagation. After many iterations, DLSS learns on its own to produce results that closely approximate the quality of 64xSS, while also learning to avoid the problems with blurring, disocclusion, and transparency that affect classical approaches like TAA. In addition to the DLSS capability described above, which is the standard DLSS mode, we provide a second mode, called DLSS 2X. In this case, DLSS input is rendered at the final target resolution and then combined by a larger DLSS network to produce an output image that approaches the level of the 64x super sample rendering - a result that would be impossible to achieve in real time by any traditional means.
Let me also clearly state that it's not a 100% perfect super sampling AA technology, but it's pretty good from what we have seen so far. Considering you run them on the Tensor cores, your shader engine is offloaded. So you're rendering a game with the perf of no AA, as DLSS runs on the Tensor cores. So very short, a normal resolution frame gets outputted in super high-quality AA. 64x super-sampled AA is comparable to DLSS 2x. All done with deep learning and run through the Tensor cores. DLSS is trained based on supersampling.

** Some high res comparison shots can be seen here, here and here. Warning: file-sizes are 1 to 2 MB each.
