
Stacked Memory and The Interposer
The sole idea behind HBM is stacking memory, multiple layers of DRAM components are integrated vertically on the package alongside the GPU/APU/SoC. Stacked memory offers the advantage of several times greater bandwidth, it increases capacity, and has a significant effect on energy efficiency compared to GDDR5 that resides off-package (far away from the GPU).
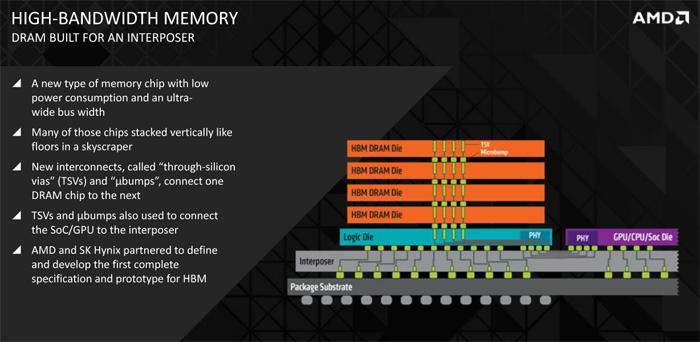
In the next few slides we'll walk you trough the new technology. But much like you have seen and heard in the NAND flash sector, HBM memory is stacked memory. In the first generation of HBM it is possible to stack four layers of graphics memory into one package. It literally is as simple as that, the memory is stacked and interconnected.
1st gen HBM is limited to 4GB Graphics memory
These stacked memory packages have limitations, in the first generation you are looking at four stacks per package with two 128MB chunks in each layer, so that is 256MB per layer. Four times 256MB = 1024MB (or 1 Gigabyte) per accumulated DRAM stack/package. Currently chip designs allow for four stacks per IC (GPU). So that is 4 packages x (4x256MB) = 4096 MB. Hence the one limitation (if you can call it that) is HBA memory being limit at a maximum 4GB of graphics memory for the graphics card.
But is it 1024-bit or 4096-Bit? Here we'll need to 'zoom in' towards one DRAM layer first. Each layer is has two memory parts each at 128-bit meaning HBM is using 128-bit wide channels so eight eight of allow for a full 1024-bit interface. Total bandwidth is in the 128GB/s range with die stacks of four DRAM dies. Important to know is that each memory controller is independently timed and controlled. So 256-bit x 4 = 1024-bit per package. If an SoC/Processor/GPU/APU is fitted with four stacked packages then that would boil down to 4096-bit (wide IO). HBA is in this sense completely different from GDDR5, let me place some variables into a table:
| GDDR5 | Per Package | HBM |
| 32-bit | Bus With | 1024-bit |
| Up-to 1750 MHz (7 GBps) | Clock Frequency | Up-to 500 MHz (1 GBps) |
| Up-to 28 GB/s per chip | Bandwith | >100 GB/s per stack |
| 1.5V | Voltage | 1.3V |
If you quickly do the math with me, HBM would allow for 400 GB/s with a graphics card running four stacks of memory in an average scenario and up-to 512 GB/s if optimal. This means that future GPUs built with HBM might reach 512GB/s to 1TB/s of main memory bandwidth in later revisions, and that is huge. If we take the latest flagship product from the competition then a GeForce Titan X with its 384-bit wide bus and 7 Gbps GDDR5 memory will get you you 337 GB/s. As you can see many roads lead to Rome, HBM is one of them. A big difference however is that HBM will bring more bandwidth for roughly 50% less power and less latency.
Combining it all - think Lego
I know it's the most simple explanation, but in order to understand the technology a little more clear think Lego. On the chip package there will be placed several segments, first and foremost the CPU or GPU (or combo) with PHY interconnect that's one lego block. Then there will be a total of four HBM memory ICs, each of the four ICs will hold four layers of memory for the first generation HBM.
Since HBM is fabbed by stacking multiple DRAM cells on-top of each other these DRAM cells must be interconnected, it is done through what’s called TSVs (Through Silicon VIAs). This is a vertical connection allowing memory to transfer more data per cycle. So yes, the while memory itself is clocked significantly lower frequency than GDDR5, it can be up to 8 maybe 9 times faster.

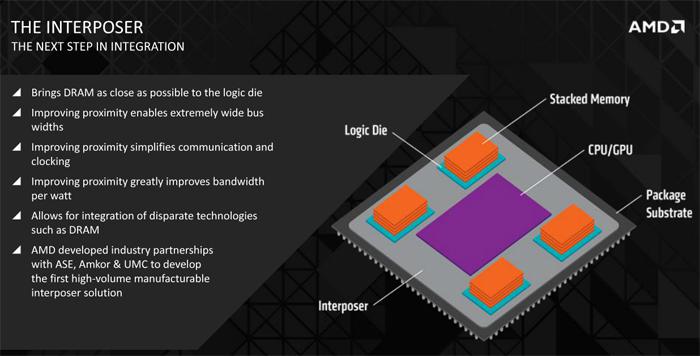
You know with Lego of you build a house it's needs that big flat base chunk of Lego to built it on ? That's the interposer. The interposer is a very thin layer on which all these components are connected, and communicate with each other, that's a whole chunk of electrical conductive wires right there. So you'll see :
- Top level - 1x CPU/GPU with PHY (interconnect)
- Top level - Four DRAM units, each has 4 layers and at the bottom a logic Die with PHY (Interconnect)
- Middle level - Interposer connecting it all
- Lower level Package Substrate
Conclusion
The primary factor to remember is that HBM achieves higher bandwidth with less power compared to DDR4 and GDDR5 thanks to the stacking of several memory chips. Whether or not the difference will be huge in terms of performance on this 1st generation remains to be seen. Will AMD be the only one using HBM ? No, Nvidia has already indicated they’ll use it for Pascal in 2016.
