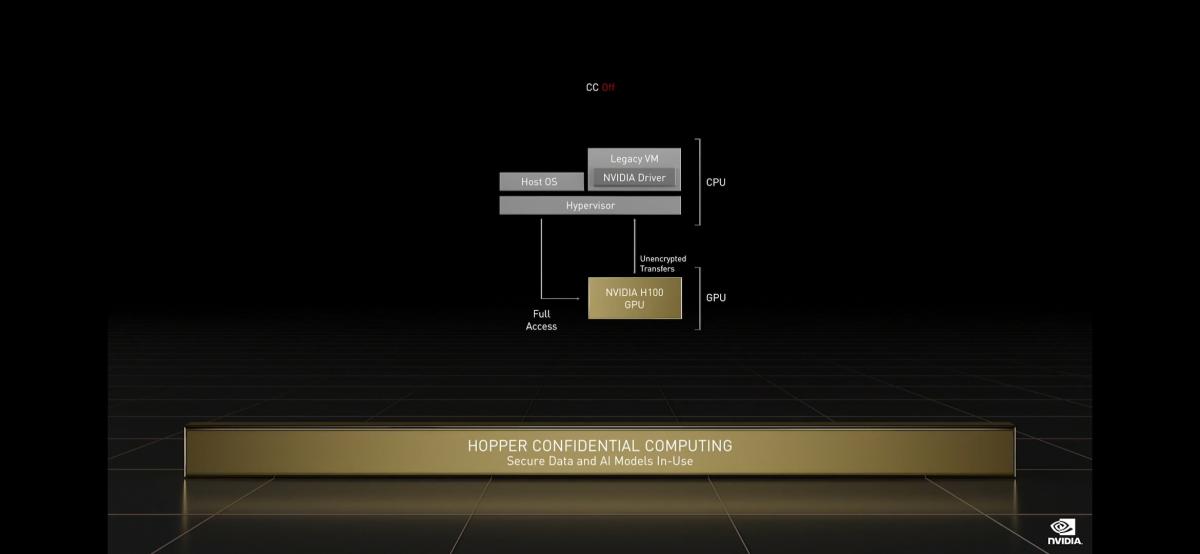
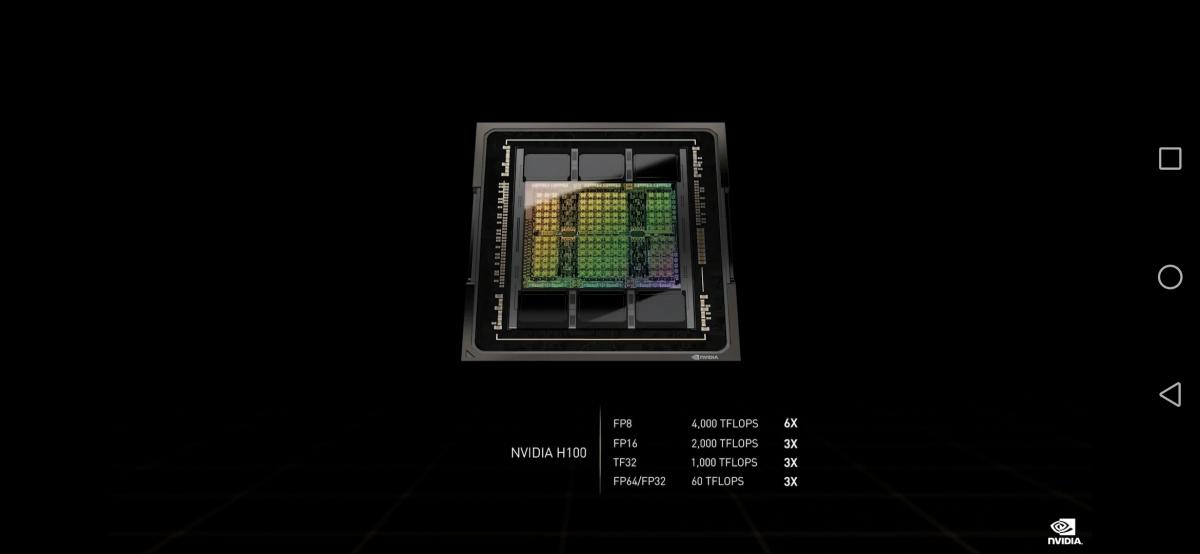
Tap into unprecedented performance, scalability, and security for every workload with the NVIDIA H100 Tensor Core GPU.
NVIDIA H100 GPUs feature fourth-generation Tensor Cores and the Transformer Engine with FP8 precision that provides up to 9X faster training over the prior generation for mixture-of-experts (MoE) models. The combination of fourth-generation NVlink, which offers 900 gigabytes per second (GB/s) of GPU-to-GPU interconnect; NVLINK Switch System, which accelerates communication by every GPU across nodes; PCIe Gen5; and NVIDIA Magnum IO™ software delivers efficient scalability from small enterprises to massive, unified GPU clusters.
Deploying H100 GPUs at data center scale delivers outstanding performance and brings the next generation of exascale high-performance computing (HPC) and trillion-parameter AI within the reach of all researchers. The NVIDIA H100 GPU with a PCIe Gen 5 board form-factor includes the following units:
- 7 or 8 GPCs, 57 TPCs, 2 SMs/TPC, 114 SMs per GPU
- 128 FP32 CUDA Cores/SM, 14592 FP32 CUDA Cores per GPU
- 4 Fourth-generation Tensor Cores per SM, 456 per GPU
- 80 GB HBM2e, 5 HBM2e stacks, 10 512-bit Memory Controllers
- 50 MB L2 Cache
- Fourth-Generation NVLink and PCIe Gen 5
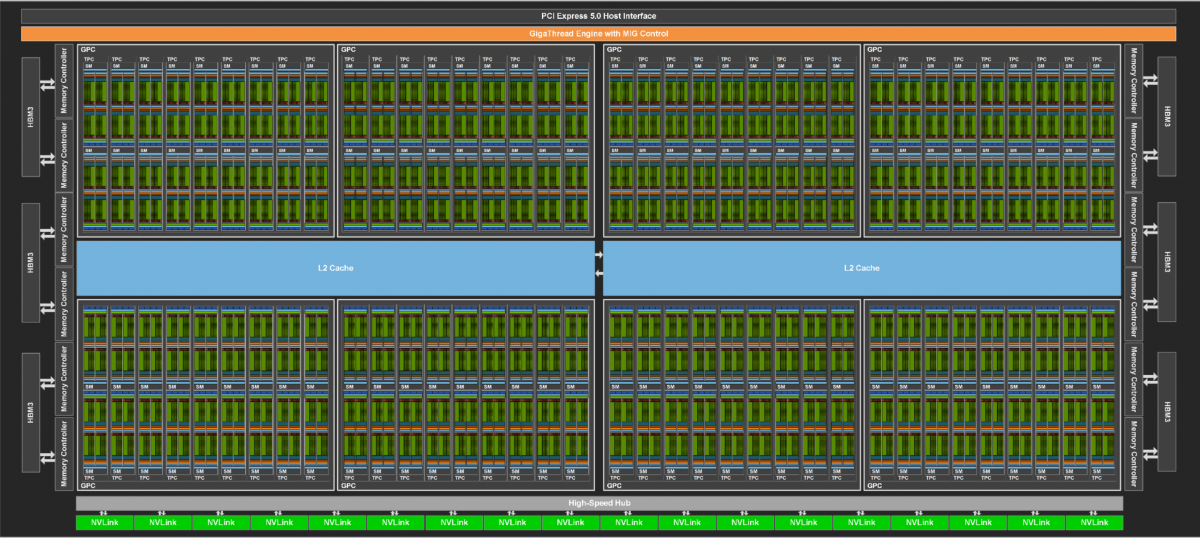
- 8 GPCs, 72 TPCs (9 TPCs/GPC), 2 SMs/TPC, 144 SMs per full GPU
- 128 FP32 CUDA Cores per SM, 18432 FP32 CUDA Cores per full GPU
- 4 Fourth-Generation Tensor Cores per SM, 576 per full GPU
- 6 HBM3 or HBM2e stacks, 12 512-bit Memory Controllers
- 60 MB L2 Cache
- Fourth-Generation NVLink and PCIe Gen 5
H100 SXM5 GPU
The H100 SXM5 configuration using NVIDIA’s custom-built SXM5 board that houses the H100 GPU and HBM3 memory stacks, and also provides fourth-generation NVLink and PCIe Gen 5 connectivity, provides the highest application performance. This configuration is ideal for customers with applications scaling to multiple GPUs in a server, and across servers. It’s available through HGX H100 server boards with 4-GPU and 8-GPU configurations. While the 4- GPU configuration includes point-to-point NVLink connections between GPUs and provides a higher CPU-to-GPU ratio in the server, the 8-GPU configuration includes NVSwitch to provide SHARP in-network reductions and full NVLink bandwidth of 900 GB/s between any pair of GPUs. The H100 SXM5 GPU is also used in the powerful new DGX H100 servers and DGX SuperPOD systems.
H100 PCIe Gen 5 GPU
The H100 PCIe Gen 5 configuration provides all the capabilities of H100 SXM5 GPUs in just 350 Watts of Thermal Design Power (TDP). This configuration can optionally use the NVLink bridge for connecting up to two GPUs at 600 GB/s of bandwidth, nearly five times PCIe Gen5. Well suited for mainstream accelerated servers that go into standard racks offering lower power per server, H100 PCIe provides great performance for applications that scale to 1 or 2 GPUs at a time, including AI Inference and some HPC applications. On a basket of 10 top data analytics, AI and HPC applications, a single H100 PCIe GPU efficiently provides 65% delivered performance of the H100 SXM5 GPU while consuming 50% of the power.
DGX H100 and DGX SuperPOD
NVIDIA DGX H100 is a universal high-performance AI system for training, inference, and analytics. DGX H100 is equipped with Bluefield-3, NDR InfiniBand, and second-generation MIG technology. A single DGX H100 system delivers an unmatched 16 petaFLOPS of FP16 sparse AI compute performance. This performance can be easily scaled up by connecting multiple DGX H100 systems into clusters known as DGX PODs or even DGX SuperPODs. A DGX SuperPOD starts with 32 DGX H100 systems, referred to as a “scalable unit”, which integrates 256 H100 GPUs connected via the new second-level NVLink switches based on thirdgeneration NVSwitch technology, delivering an unprecedented one exaFLOP of FP8 sparse AI compute performance.
HGX H100
As workloads explode in complexity there’s a need for multiple GPUs to work together with extremely fast communication between them. NVIDIA HGX H100™ combines multiple H100GPUs with the high-speed interconnect powered by NVLink and NVSwitch to enable the creation of the world’s most powerful scale-up servers. HGX H100 is available as a server building block in the form of integrated baseboards in four or eight H100 GPUs configurations. Four GPU HGX H100 offers fully interconnected point to point NVLink connections between GPUs, while the eight GPU configuration offers full GPU-to-GPU bandwidth through NVSwitch. Leveraging the power of H100 multi-precision Tensor Cores, an 8-way HGX H100 provides over 32 petaFLOPS of deep learning compute performance using sparse FP8 operations. HGX H100 enables standardized high-performance servers that provide predictable performance on various application workloads, while also enabling faster time to market for NVIDIA’s ecosystem of partner server makers.
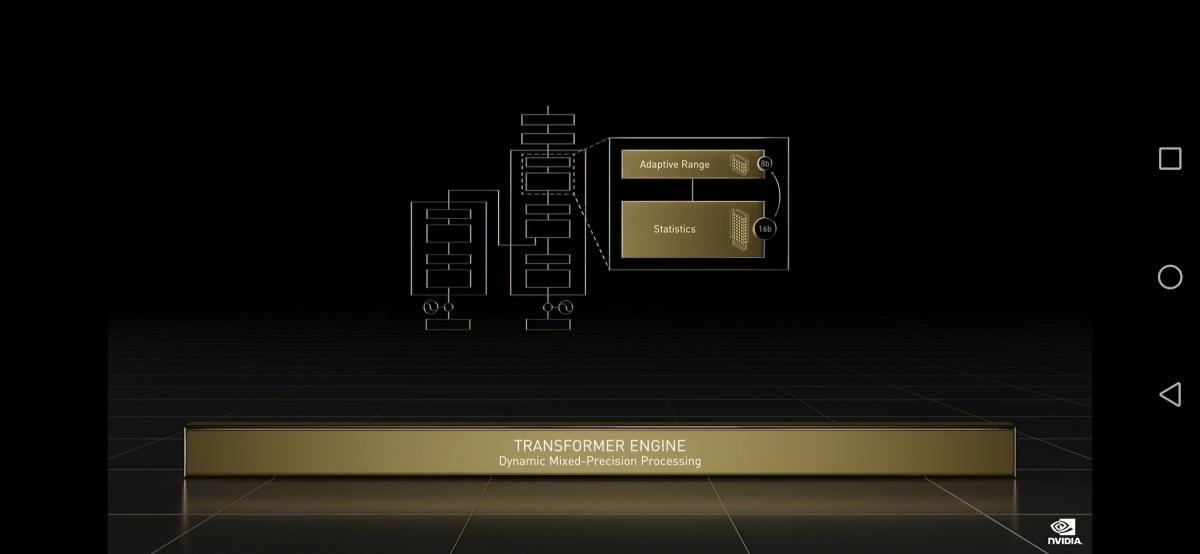
H100 further extends NVIDIA’s market-leading inference leadership with several advancements that accelerate inference by up to 30X and deliver the lowest latency. Fourth-generation Tensor Cores speed up all precisions, including FP64, TF32, FP32, FP16, and INT8, and the Transformer Engine utilizes FP8 and FP16 together to reduce memory usage and increase performance while still maintaining accuracy for large language models.
00 triples the floating-point operations per second (FLOPS) of double-precision Tensor Cores, delivering 60 teraFLOPS of FP64 computing for HPC. AI-fused HPC applications can also leverage H100’s TF32 precision to achieve one petaFLOP of throughput for single-precision matrix-multiply operations, with zero code changes.
H100 also features new DPX instructions that deliver 7X higher performance over A100 and 40X speedups over CPUs on dynamic programming algorithms such as Smith-Waterman for DNA sequence alignment and protein alignment for protein structure prediction.
NVIDIA Grace Hopper
The Hopper Tensor Core GPU will power the NVIDIA Grace Hopper CPU+GPU architecture, purpose-built for terabyte-scale accelerated computing and providing 10X higher performance on large-model AI and HPC. The NVIDIA Grace CPU leverages the flexibility of the Arm® architecture to create a CPU and server architecture designed from the ground up for accelerated computing. The Hopper GPU is paired with the Grace CPU using NVIDIA’s ultra-fast chip-to-chip interconnect, delivering 900GB/s of bandwidth, 7X faster than PCIe Gen5. This innovative design will deliver up to 30X higher aggregate system memory bandwidth to the GPU compared to today's fastest servers and up to 10X higher performance for applications running terabytes of data.
Product Specifications
| Form Factor | H100 SXM | H100 PCIe |
|---|---|---|
| FP64 | 30 teraFLOPS | 24 teraFLOPS |
| FP64 Tensor Core | 60 teraFLOPS | 48 teraFLOPS |
| FP32 | 60 teraFLOPS | 48 teraFLOPS |
| TF32 Tensor Core | 1,000 teraFLOPS* | 500 teraFLOPS | 800 teraFLOPS* | 400 teraFLOPS |
| BFLOAT16 Tensor Core | 2,000 teraFLOPS* | 1,000 teraFLOPS | 1,600 teraFLOPS* | 800 teraFLOPS |
| FP16 Tensor Core | 2,000 teraFLOPS* | 1,000 teraFLOPS | 1,600 teraFLOPS* | 800 teraFLOPS |
| FP8 Tensor Core | 4,000 teraFLOPS* | 2,000 teraFLOPS | 3,200 teraFLOPS* | 1,600 teraFLOPS |
| INT8 Tensor Core | 4,000 TOPS* | 2,000 TOPS | 3,200 TOPS* | 1,600 TOPS |
| GPU memory | 80GB | 80GB |
| GPU memory bandwidth | 3TB/s | 2TB/s |
| Decoders | 7 NVDEC7 JPEG | 7 NVDEC7 JPEG |
| Max thermal design power (TDP) | 700W | 350W |
| Multi-Instance GPUs | Up to 7 MIGS @ 10GB each | |
| Form factor | SXM | PCIe |
| Interconnect | NVLink: 900GB/s PCIe Gen5: 128GB/s | NVLINK: 600GB/s PCIe Gen5: 128GB/s |
| Server options | NVIDIA HGX?H100 Partner and NVIDIA-Certified Systems?with 4 or 8 GPUs NVIDIA DGX?H100 with 8 GPUs | Partner and NVIDIA-Certified Systems with 1?8 GPUs |