With new DPX instructions, the NVIDIA Hopper GPU architecture introduced today at GTC will speed dynamic programming — a problem-solving approach utilized in algorithms for genomics, quantum computing, route optimization, and other applications — by up to 40x.
DPX is an instruction set included into NVIDIA H100 GPUs that will assist developers in writing code to gain speedups on dynamic programming techniques in a variety of sectors, including illness detection, quantum simulation, graph analytics, and routing optimizations.
What Is Dynamic Programming?
Developed in the 1950s, dynamic programming is a popular technique for solving complex problems with two key techniques: recursion and memoization. Recursion involves breaking a problem down into simpler sub-problems, saving time and computational effort. In memoization, the answers to these sub-problems — which are reused several times when solving the main problem — are stored. Memoization increases efficiency, so sub-problems don’t need to be recomputed when needed later on in the main problem. DPX instructions accelerate dynamic programming algorithms by up to 7x on an NVIDIA H100 GPU, compared with NVIDIA Ampere architecture-based GPUs. In a node with four NVIDIA H100 GPUs, that acceleration can be boosted even further.
Availability
NVIDIA DGX H100 systems, DGX PODs and DGX SuperPODs will be available from NVIDIA’s global partners starting in the third quarter.
Use Cases Span Healthcare, Robotics, Quantum Computing, Data Science
Dynamic programming is commonly used in many optimization, data processing and omics algorithms. To date, most developers have run these kinds of algorithms on CPUs or FPGAs — but can unlock dramatic speedups using DPX instructions on NVIDIA Hopper GPUs.
Omics
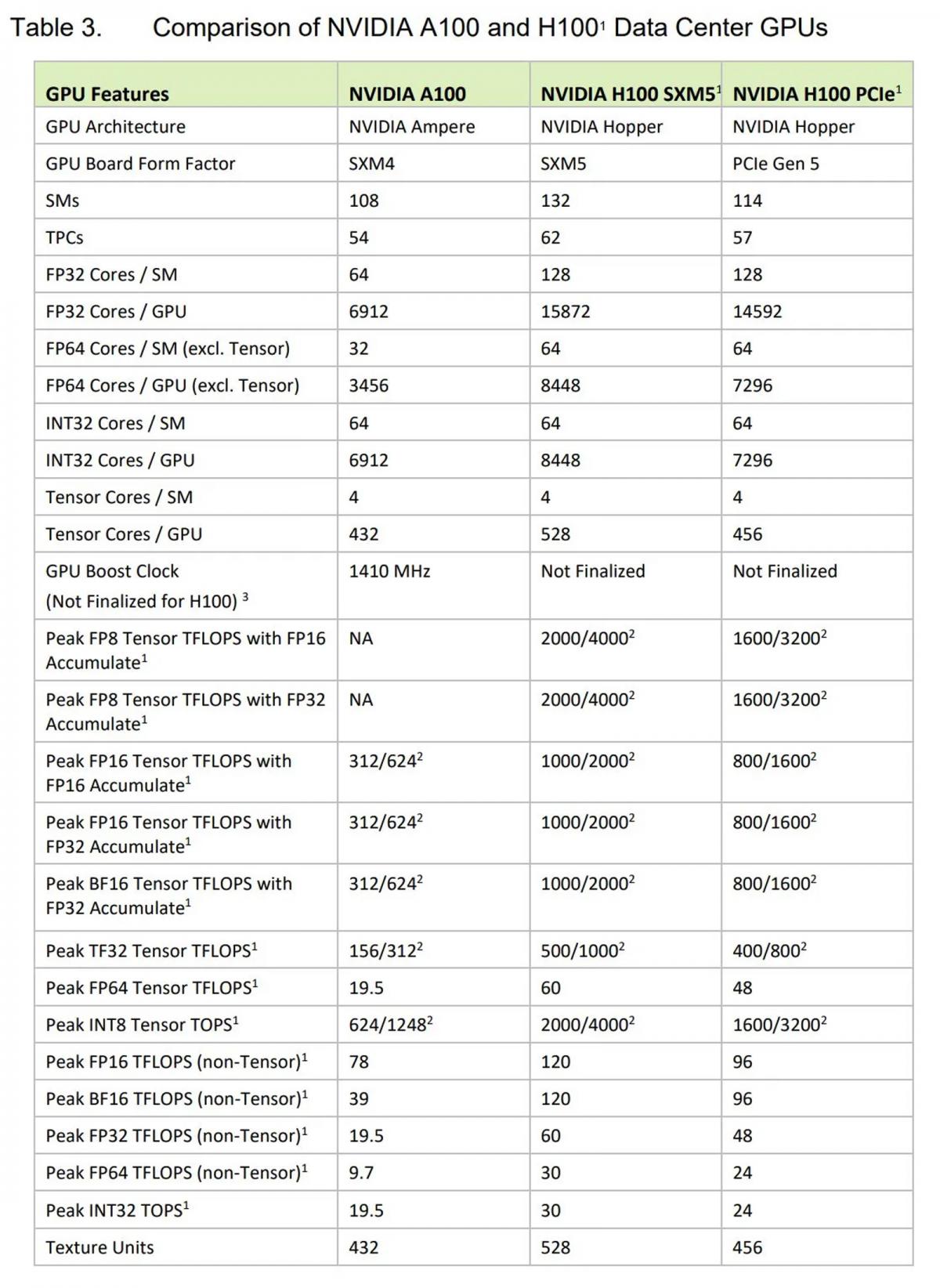
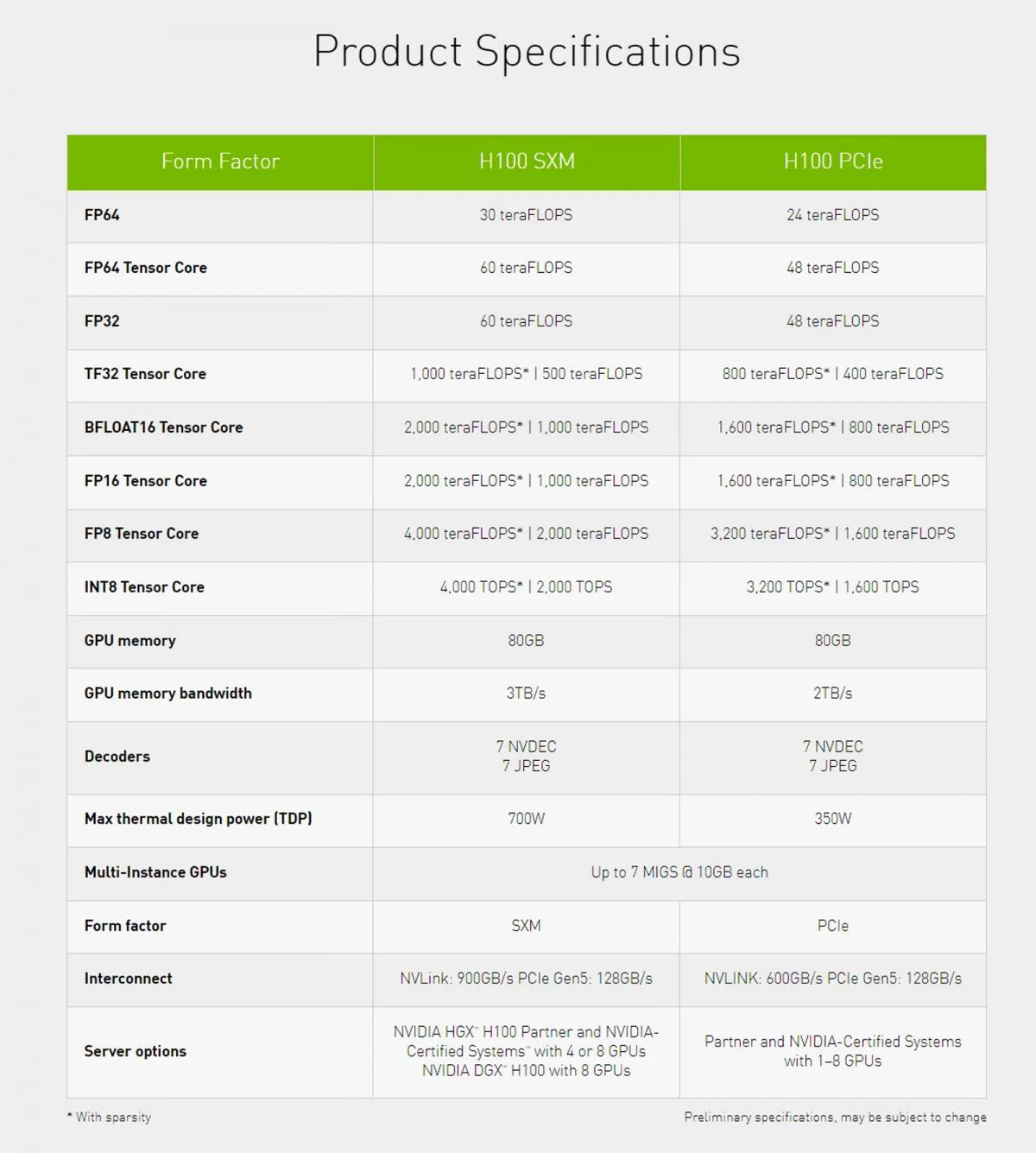
| Preliminary NVIDIA Data-Center GPUs Specifications | ||||
|---|---|---|---|---|
| NVIDIA H100 | NVIDIA A100 | NVIDIA Tesla V100 | NVIDIA Tesla P100 | |
| GPU | GH100 | GA100 | GV100 | GP100 |
| Transistors | 80 Billion | 54 Billion | 21 Billion | 15 Billion |
| Die Size | 814 mm² | 828mm² | 815 mm² | 610 mm² |
| Architecture | Hopper | Ampere | Volta | Pascal |
| Fabrication Node | TSMC N4 | TSMC N7 | 12nm FFN | 16nm FinFET+ |
| GPU Clusters | 132 | 108 | 80 | 56 |
| CUDA Cores | 16896/14592 | 6912 | 5120 | 3584 |
| L2 Cache | 50MB | 40MB | 6MB | 4MB |
| Tensor Cores | 528/456 | 432 | 320 | - |
| Memory Bus | 5120-bit | 5120-bit | 4096-bit | 4096-bit |
| Memory Size | 80 GB HBM2e | 40/80GB HBM2e | 16/32 HBM2 | 16GB HBM2 |
| TDP | 700W/350W | 250W/300W/400W | 250W/300W/450W | 250W/300W |
| Interface | SXM5/PCIe Gen5 | SXM4/PCIe Gen4 | SXM2/PCIe Gen3 | SXM/PCIe Gen3 |
| Launched | 2022 | 2020 | 2017 | 2016 |
For example, the Smith-Waterman and Needleman-Wunsch dynamic programming algorithms are used for DNA sequence alignment, protein classification and protein folding. Both use a scoring method to measure how well genetic sequences from different samples align.Omics covers a range of biological fields including genomics (focused on DNA), proteomics (focused on proteins) and transcriptomics (focused on RNA). These fields, which inform the critical work of disease research and drug discovery, all rely on algorithmic analyses that can be sped up with DPX instructions. Smith-Waterman produces highly accurate results, but takes more compute resources and time than other alignment methods. By using DPX instructions on a node with four NVIDIA H100 GPUs, scientists can speed this process 35x to achieve real-time processing, where the work of base calling and alignment takes place at the same rate as DNA sequencing. This acceleration will help democratize genomic analysis in hospitals worldwide, bringing scientists closer to providing patients with personalized medicine.
Route Optimization
Finding the optimal route for multiple moving pieces is essential for autonomous robots moving through a dynamic warehouse, or even a sender transferring data to multiple receivers in a computer network. To tackle this optimization problem, developers rely on Floyd-Warshall, a dynamic programming algorithm used to find the shortest distances between all pairs of destinations in a map or graph. In a server with four NVIDIA H100 GPUs, Floyd-Warshall acceleration is boosted 40x compared to a traditional dual-socket CPU-only server. Paired with the NVIDIA cuOpt AI logistics software, this speedup in routing optimization could be used for real-time applications in factories, autonomous vehicles, or mapping and routing algorithms in abstract graphs.