
Article Page 3 - Blender 2.82 OpenGL/CUDA/OptiX
GPU Performance - Blender 2.82
Blender v2.81a has recently been updated towards build 2.82 and offers a wide variety of options and .. APIs, depending on your graphics card. We fire off a scene where we render a Classroom - we only allow the GPU to render in the benchmark application. There are API related challenges to address with Blender though:
- AMD Radeon cards support OpenCL solely
- NVIDIA GeForce cards up to Pascal support CUDA - but not OpenCL or Optix
- NVIDIA GeForce RTX cards based on Turing can be assigned CUDA or OptiX - but not OpenCL
That OptiX option you need to keep an eye on. OptiX only works on RTX cards; that said however, not Turing architecture-based cards like the GTX 1660 series. It will prove to be (by far) the fastest renderer for compatible GeForce graphics cards. OptiX Application Acceleration Engine is a ray tracing API. The computations are offloaded to the GPUs through either the low-level or the high-level API introduced with CUDA. CUDA is only proprietary towards Nvidia's GPU products. To show you the performance benefits between CUDA and the OptiX code path, well here is an example of an RTX 2060 Super in CUDA and Optix:
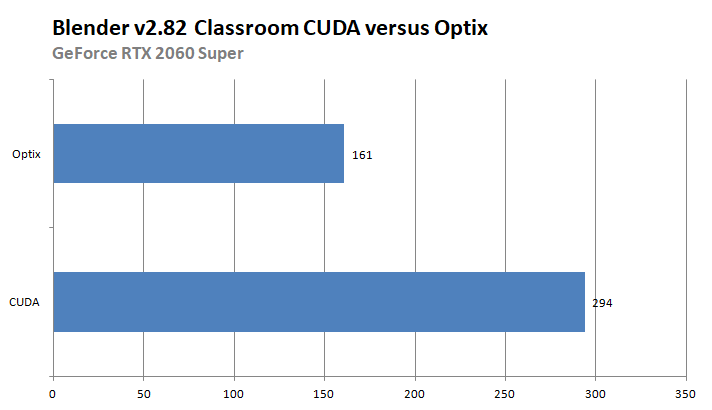
Score in second to render / lower is faster
As you can see the Optix code path is greatly faster if you have a compatible graphics card (RTX). But let's chart things up. With three APIs for which some work on some cards but not on others, that's going to be a bit of a challenge to chart up, as literally you'd be getting a cluttered confusing chart like this:
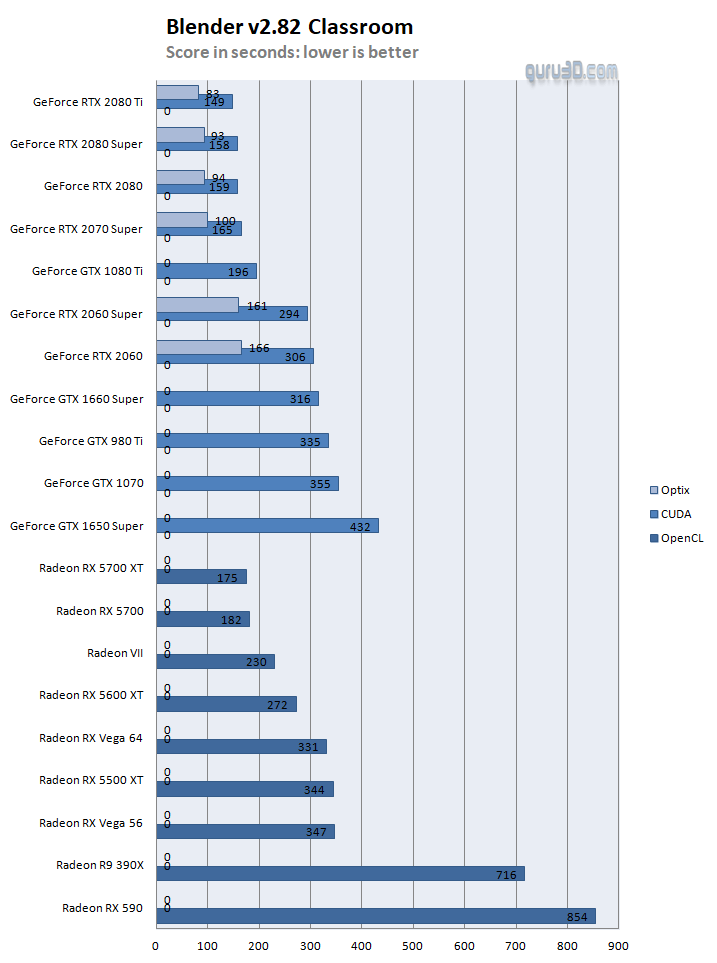
So yes, albeit a valid chart, it will be too confusing. To address that we'll compare brand compatible API to the graphics cards tested, first Radeon OpenCL versus GeForce CUDA, let's re-visit and plot a chart:
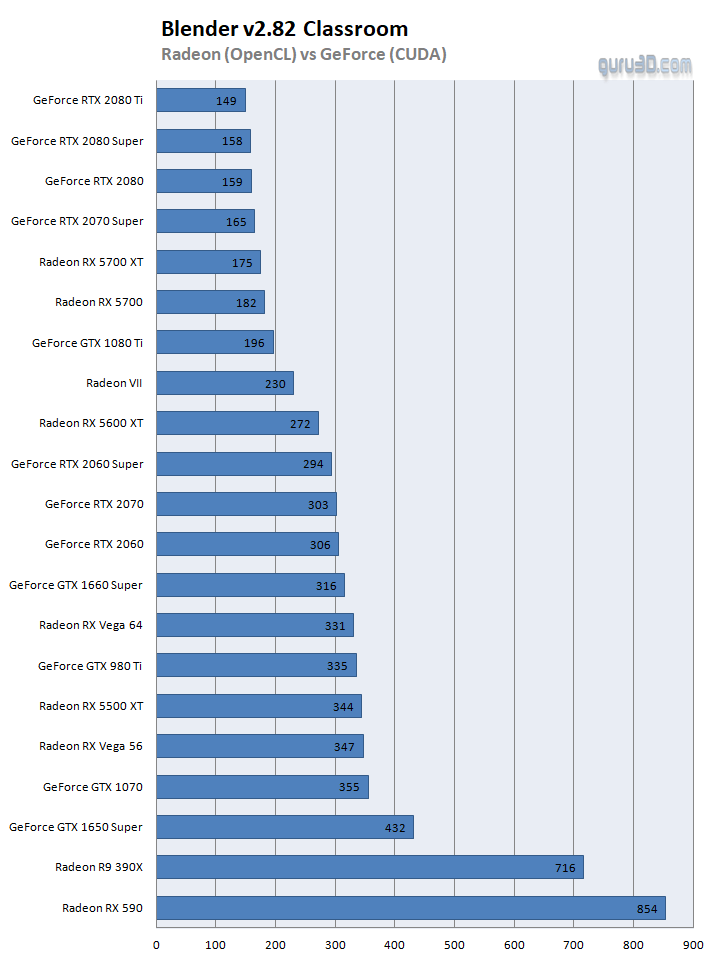
Al GeForce cards of recent years can utilize the CUDA (closed API), which is fairly close to OpenCL (open API). Here we can see twenty cards rendering the classroom scene. OpenCL is applied for Radeon and CUDA for GeForce. Mind you that we cannot select OpenCL on the GeForce cards, ergo CUDA is selected. What you'll notice is that Hawaii/Grenada and Polaris perform dramatically. For Polaris that surprised me a little. However, Vega and NAVI with their updated GCN architectures certainly are strong competitors in the current day graphics compute arena. Aside from the Radeon VII, the cards perform more or less in the expected performance bracket.
For Geforce cards then, if you look at the premium (top) stack, the perf is much closer towards each other so yes, there is further optimization possible there. So let's fire up the Optix compatible cards, enable that as an option and compare them to Radeons with OpenCL:
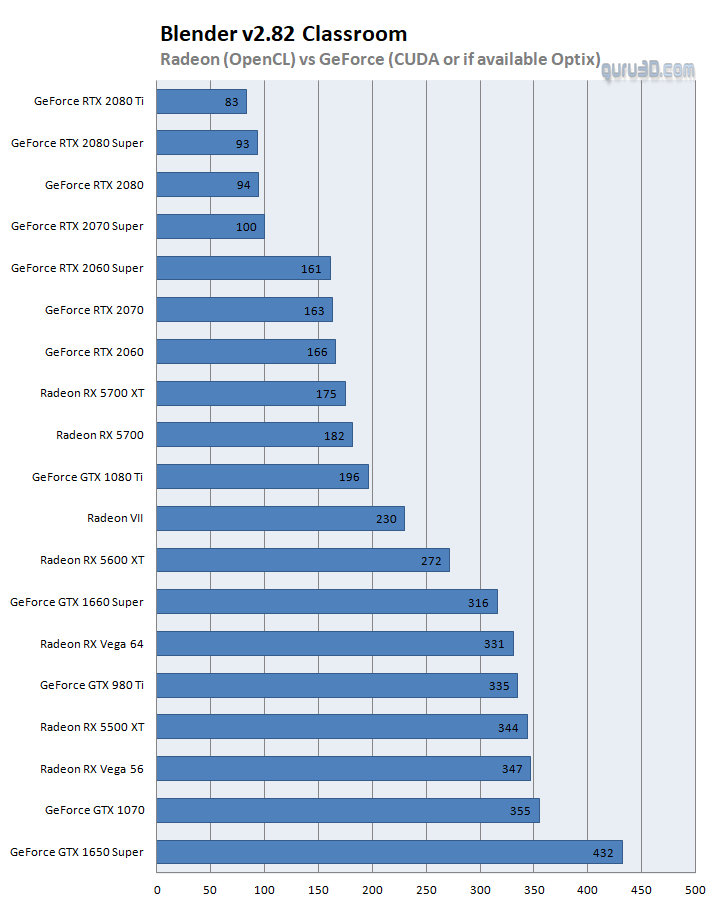
In this chart above, we have enabled Optix where it could be enabled, which is the RTX series. Where OptiX is not possible we run CUDA, and then the Radeon have just the one option, OpenCL. A 1660 Ti, for example, is Turing based, however, the OptiX codepath is not working here. Optix clearly is a highly optimized API that you absolutely should use with Blender (if you have a Turing RTX or newer based graphics cards). Now let's normalize it relative to percentages:
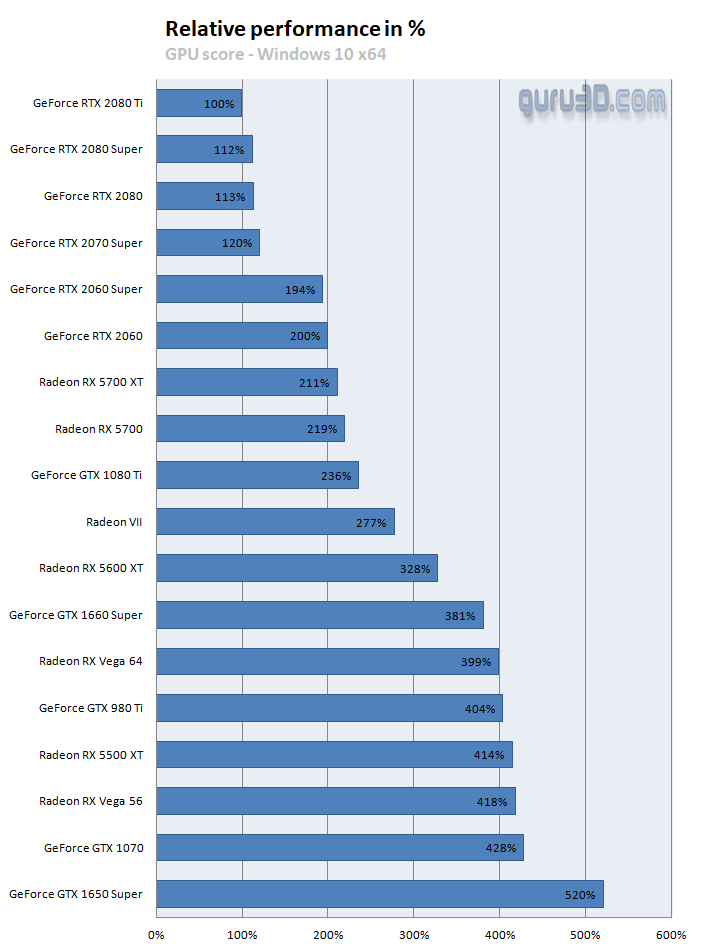
Concluding
And with these final words written, we end this little writeup. We hope to have answered some questions from our community and reader base. The results drawn will be updated and added to our future graphics card reviews. People do need to understand that in the world of compute rendering, nothing is as simple as it seems. That is the one conclusion you can deduct from this article. With AMD Radeon sticking solely to OpenCL, and NVIDIA offering CUDA and OptiX a 1:1 comparison certainly is not easy or arguably fair. In the end though, we assume that the end-user will always opt for the most reliable and fastest solution at hand. And exactly that, needs to be the basis of comparison in compute rendering, as your workload turnaround time to final output is the only dominant factor. Less seconds rendered is less money spent. We'll continue testing and using these titles, and to the Chaos group, we'd like to plea to open up OpenCL support in VRAY NEXT for Radeon graphics cards, as being CUDA only, really was a bit of a buzz-kill in the year 2020.
To be continued.
- Sign up to receive a notification when we publish a new article
- Or go back to Guru3D's front page.
