
Alpha Lyrae
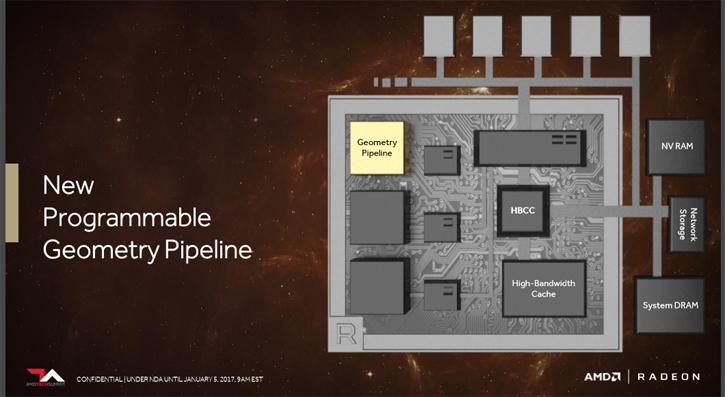
A more programmable GPU - programmable geometry pipeline
We did already mention that VEGA really is a new architecture, we just talked briefly about the HBM2 graphics memory and controller, we now move into the graphics pipeline. GPUs accelerate 2D and 3D operations. 2D operations usually mean what users are seeing in their windowed operating system environment, while 3D rendering equals to games or say CAD applications that draw images using polygons and textures. It is a combination of triangles, compute (and slowly but steadily even ray-tracing) to calculate a final synthetic image. The basic functionality of your graphics card graphics pipeline is to transform your 3D scene, given a certain camera position and camera orientation, into a 2D image. In that process you want to be flexible and thus it gets better once stages get programmable opposed to being a fixed solution. Your GPU rendering pipeline is mapped onto current graphics acceleration hardware such that the input to the GPU is in the form of vertices. These vertices undergo transformation and (per-vertex) lighting. Still with me?
At this point in GPU pipelines, a custom vertex shader program can be used to manipulate the 3D vertices prior to rasterization. Traditionally once transformed and lit, the vertices undergo clipping and rasterization resulting in fragments. A custom (second) shader program can then be run on each fragment before the final pixel values are output to the frame buffer for display. The graphics pipeline is properly suited to the rendering process because it allows the GPU to function as a stream processor since all vertices and fragments can be thought of as independent units. This allows all stages of the pipeline to be used simultaneously for different vertices or fragments as they work their way through the pipe. In addition to pipelining vertices and fragments, their independence allows graphics processors to use parallel processing units to process multiple vertices or fragments in a single stage of the pipeline at the same time.
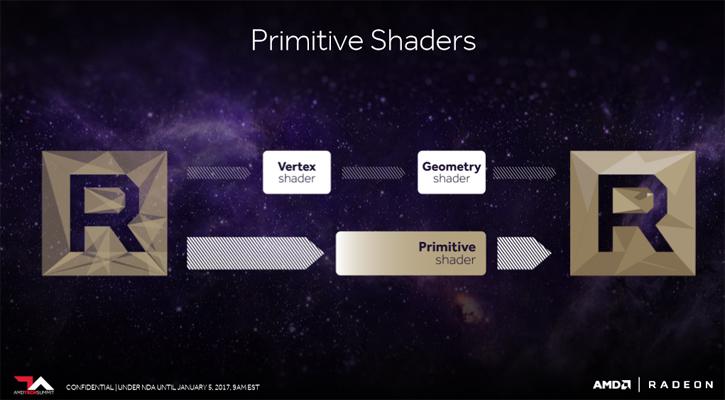
A shader really is simple code, little programs that describe the behavior of either a vertex or a pixel taking inputs and transform them into outputs. In general there always have been three primary stages: Vertex, Geometry and Pixel shader stages (there's also fragment, hull, domain and other shaders but forget these for now). It starts with Vertex shaders, these describe things like position, texture coordinates, colors, etc. of a vertex, while pixel shaders describes color, z-depth and alpha value of a pixel. Shaders thus provide a programmable alternative towards a hard-coded (fixed) approach.
With that explained we can now better understand a geometry shader. The geometry shader has the ability to create new geometry on the fly using the output of the vertex shader as input in roughly the last stages of the 3D pipeline, it can alter geometry. The geometry shader can work on a complete primitive (triangle, line, quads or point), or even one geometry shader could handle multiple geometric primitives. So it can change existing primitives in the sense that it for example could insert new primitives but then again could also remove existing primitives, thus change the geometry of that triangle (or line). The primitive stage will break geometry down into the most elementary primitives such as points, lines and triangles. You will have noticed that a Primitive Shader now also is listed and thus processed.
So with VEGA AMD added a fully programmable geometry pipeline, which is new and was been added into the architecture. The benefit of a geometry shader can be found in the ability to generate a varying amount of primitives. AMD claims that the new programmable geometry pipeline offers over 2x throughput per clock over previous solutions. And in magical world of the GPU, anything x2 is a lot.

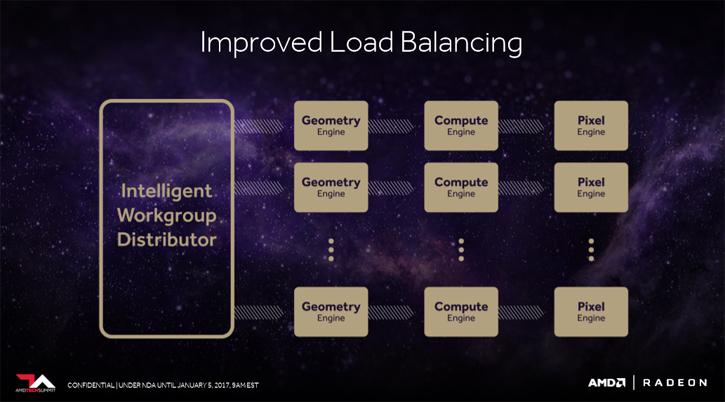
The Compute Unit (CU) then, terminology is often revamped: AMD calls the CU an NCU now, aka Next Generation Compute Unite. Obviously simply described a compute unit is a stream multiprocessor cluster or back in the days we all called it SIMD engine, in an AMD GPU. Each compute unit has several processing elements (ALU/stream processor).
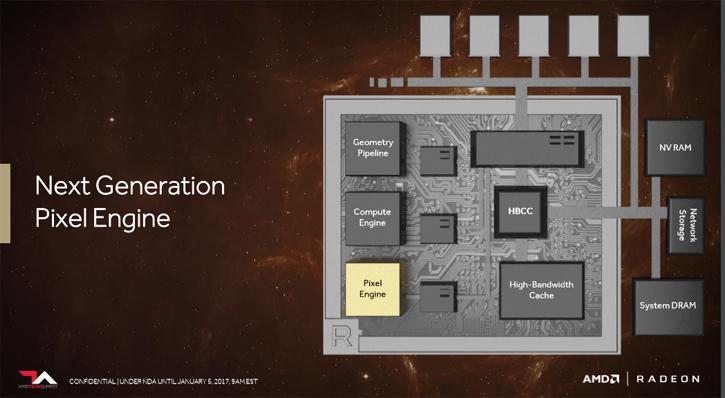
The Next gen compute engine (Vega NCU) offers 512 operations on 8-bit per clock and from there on-wards halved with 256 16-bit ops per clock (for game rendering) and 128 32-bit ops per clock.

The double precision rate is now actually configurable. AMD also stated that the NCU is optimized for higher clock speeds and higher values in instructions per cycle. We expect, and this value is unconfirmed, that Vega 10 will feature 4096 stream processors, spread across 64 NCUs with each NCU thus holding 64 streaming multiprocessors). AMD is making a nice claim in the upper slide there, "NCU is optimized for higher clock speeds", this could indicate that VEGA, much like Pascal, could reach high base and boost clock freqeuncies. That however remains speculation from my side.
